Big Iron to Big Data Integration
Integração de dados simples e eficiente, do Big Iron ao Big Data.O DMX-h apresenta uma interface única e intuitiva para acessar e integrar todas as suas fontes de dados, sejam batch ou streaming, desde o Mainframe até o Hadoop. Ele abstrai a complexidade do framework de execução e mantém a máxima performance automaticamente.
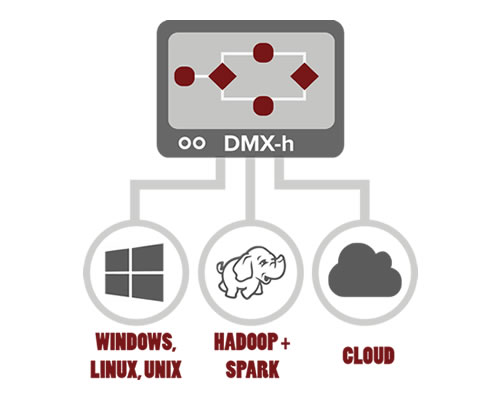
Construa e gerencie todo o data pipeline com workflow integrado na mesma interface, desde a ingestão de fontes heterogêneas até a distribuição dos dados integrados, e processe as tarefas de integração em múltiplos frameworks de forma transparente, seja em servidor tradicional Linux/Unix/Windows ou em cluster Hadoop com Spark ou MapReduce.

O DMX-h torna a sua arquitetura de integração extremamente ágil e pronta para aproveitar os benefícios das novas plataformas em contínua evolução. Além disso, ele povoa automaticamente o data lake a partir de milhares de tabelas de bases heterogêneas e cria automaticamente os metadados correspondentes no Hadoop.

O DMX-h também possui Change Data Capture do Mainframe para o Hadoop, mantendo suas tabelas Hive em sincronia com as alterações do DB2 z/OS em tempo real e sem impacto de CPU no Mainframe.
Entre em contato agora mesmo e tire suas dúvidas.
Entenda melhor como podemos oferecer uma gestão de dados mais eficiente para o seu negócio.